Shimul Paul
WELCOME TO MY WEBSITE!

University: Frankfurt University of Applied Sciences

University: Ahsanullah University of Science and Technology
CGPA(on a scale of 4): 3.766
Thesis Supervisor: Faisal Muhammad Shah
Thesis Topic:
Deep Learning
based Bengali Image Caption Generation
Ninth position in class and achieved Dean's
List of Honor

Mollartek Udayan
Bidyalay
Educational Field: Science
Result: GPA 5.00 out of 5.00

Mollartek Udayan Bidyalay
Educational Field: Science
Result: GPA 5.00 out of 5.00

CHAMPION in Robo Soccer Competition, Codeware19 (INTRA AUST ROBO SOCCER COMPETITION)
ISSUER: Department of CSE, Ahasanullah University of Science and Technology (AUST)

CHAMPION in Programming Competition, Codeware19 (INTRA AUST PROGRAMMING CONTEST)
ISSUER: Department of CSE, Ahasanullah University of Science and Technology (AUST)

Top 25 at Hult Prize at AUST
ISSUER: HULT Prize Committee

Award was given in 2020 for achieving the position at top 100.
ISSUER: Banglalink Digital

Educational, Specialization in Deep Neural Networks in the year 2020
ISSUER: Coursera

Educational, Specialization in Technical Support year 2020
ISSUER: Coursera

Educational, Specialization in Sequences in the year 2020.
ISSUER: Coursera

Educational, Specialization in Sequence Models in the year 2020.
ISSUER: Coursera

Professional Course on MERN stack.
ISSUER: Programming Hero
Duration: June 2025 – Present
Student Assistant (Full Stack Software Developer) at
Goethe University Frankfurt
Duration: May 2022 - May 2023
A part-time Lecturer at
Ahsanullah University of Science and Technology
This project investigates how Free Prompting vs. Assisted Prompting affect response quality, accuracy, and task completion time in open-ended LLM tasks. Users participation helps evaluate the impact of assistance on outcomes. Findings may be presented at scientific/professional meetings or published in journals and proceedings.
This is a webshop application that integrates a Django backend with RESTful APIs, a React frontend powered by Vite for efficient development, and MySQL for data storage. The entire application is containerized using Docker and Docker Compose, ensuring seamless deployment and scalability.
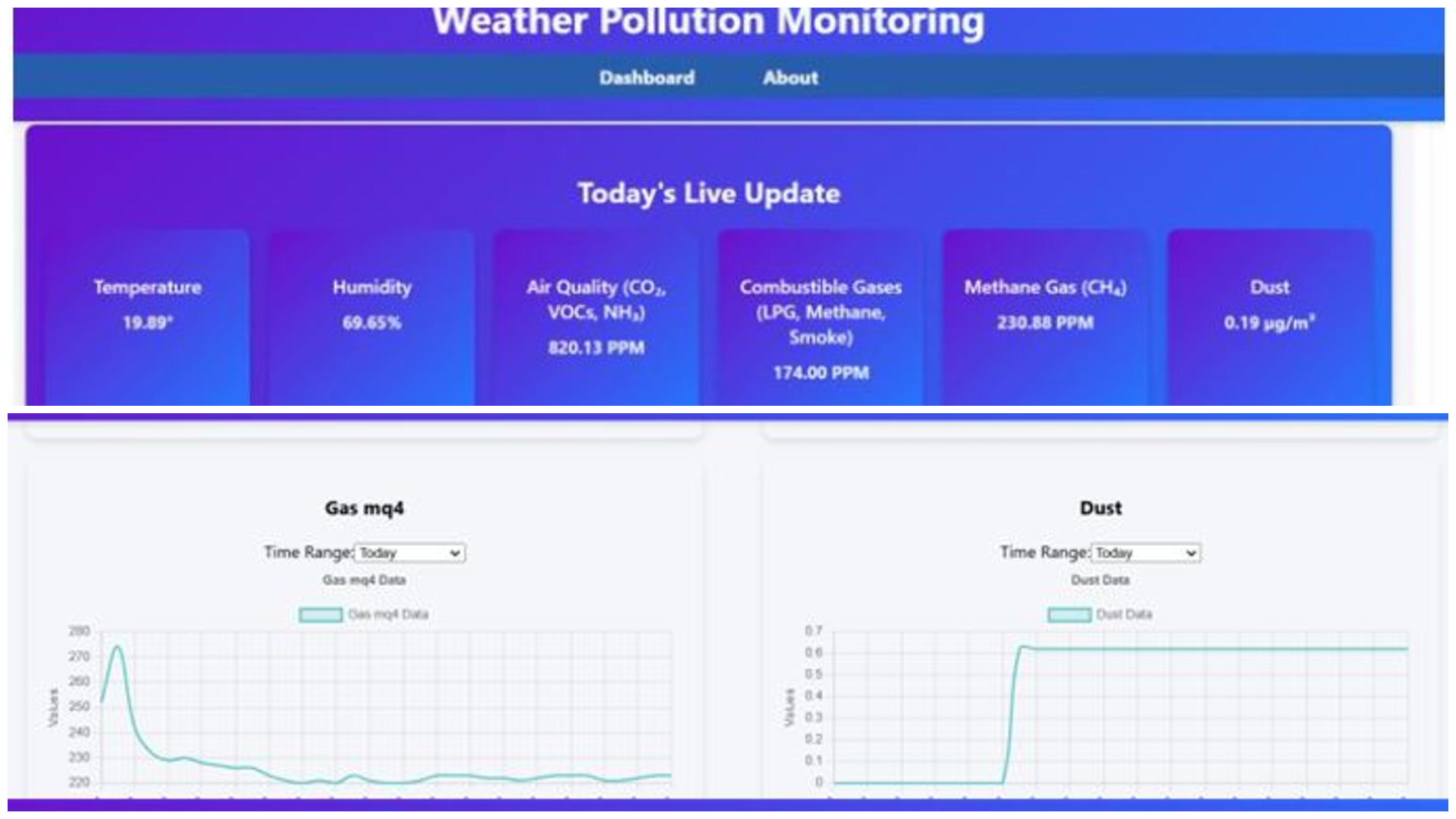
This project introduces a real-time, low-cost IoT-based weather and pollution monitoring system using ESP32 and environmental sensors. With a Django-MySQL backend and a React.js dashboard, it enables live data visualization, historical analysis, and instant alerts via email and SMS. Deployed via Docker, the system supports smart city, healthcare, and agricultural use, promoting data-driven decisions and sustainable urban planning.
Here are some problems to make some design using the WebGL API.
In this project, two sites were made, one used my computer as the server and another was created using VMware. The site_link was run by the VMware site. Different tasks could be performed in these sites.
The Information Pool System is an online-based website that showcase news from various sites in one place. It aims to be the one-stop destination for people seeking information about current events of the world as well as find classfields according to their requirements.
This project 'BondhuShop.com' is aimed at developing a web application that depicts online shopping of clothes and gift items and purchasing through 'Cash on Delivery' method only.This application involves most of the features of online shopping.
This project(Restaurant billing management system) made with the help of java,mysql .In the system some specific users can log in and generate the bill only by providing the item's quantity and vat percentage. The bill can be printed as a token. Only the main admin can add or delete users by id from database by logging in. He /She can also add or delete food item from the database.
This project(Shooting game) made with visual studio 10. the main page has 5 states, the 1st one starts the game. The objective of the 1st level of the game is to shoot the birds and collect points in a certain time and go to next level. In the 2nd level shooter has to shoot the birds and collect a certain points in certain time to win the game.The game will be over if the shooter loses all the lives by missing the targets and collecting life killing gems.In both the levels shooter can collect life increasing gems also.










Researchgate: researchgate.net/A Hybridized Deep Learning Method for Bengali Image Captioning
An omnipresent challenging research topic in computer vision is the generation of captions from an input image. Previously, numerous experiments have been conducted on image captioning in English but the generation of the caption from the image in Bengali is still sparse and in need of more refining. Only a few papers untill now have worked on image captioning in Bengali. Hence, we proffer a standard strategy for Bengali image caption generation on two different sizes of the Flickr8k dataset and BanglaLekha dataset which is the only publicly available Bengali dataset for image captioning. Afterward, the Bengali captions of our model were compared with Bengali captions generated by other researchers using different architectures. Additionally, we employed a hybrid approach based on InceptionResnetV2 or Xception as Convolution Neural Network and Bidirectional Long Short-Term Memory or Bidirectional Gated Recurrent Unit on two Bengali datasets. Furthermore, a different combination of word embedding was also adapted. Lastly, the performance was evaluated using Bilingual Evaluation Understudy and proved that the proposed model indeed performed better for the Bengali dataset consisting of 4000 images and the BanglaLekha dataset.
Researchgate: researchgate.net/Bengali Image Captioning with Visual Attention
Attention based approaches has been manifested to be an effective method in image captioning. However, attention can be used on text called semantic attention or on image which in known as spatial attention. We chose to implement the latter as the main problem of image captioning is not being able to detect objects in image properly. In this work, we develop an approach which extracts features from images using two different convolutional neural network and combines the features with an attention model in order to generate caption with an RNN. We adapted Xception and InceptionV3 as our CNN and GRU as our RNN. Moreover, we Evaluated our proposed model on Flickr8k dataset translated into Bengali. So that captions can be generated in Bengali using visual attention.
Researchgate: researchgate.net/Bengali Image Captioning with Visual Attention
Image captioning using Encoder-Decoder based approach where CNN is used as the Encoder and sequence generator like RNN as Decoder has proven to be very effective. However, this method has a drawback that is sequence data must be processed in order. The beginning of the sequence must be processed before the end. To solve this issue we utilized the transformer-based model to caption images in Bengali. Unlike other sequence models, the Transformer uses an attention mechanism that provides context for any position in the input sequence. For instance, if the input data is a natural language sentence, the transformer does not need to process the beginning of the sentence before the end. As a result, we utilized three different Bengali datasets to generate Bengali captions from images using the Transformer model. Additionally, we fine-tuned the number of heads and layers in the transformer of all three Bengali datasets. Finally, we compared the result of the transformer-based model with a visual attention-based approach to caption images in Bengali.
In recent years, the breakdown of most human causes that hampers a large number of people is verbal abuse. The most noticeable fact is that most of the verbal abuse is made online by people behind the screen. While this problem has occurred with growing modern technologies, a modern solution is needed to solve the drawback. The growing rate of abusive comments and hate speech online is rapidly increasing on a large scale, and manual reports and corrections cannot help this critical situation. This proposed model introduces automation of the hate speech filtering process through deep learning. This work uses only Bengali datasets to find the real classification, as many Bengali and English mixed research works are available in this field. Using the intelligent automated classification of text comments in a limited resource-constrained language (example: Bengali) is critical for several reasons. This proposed system classifies 'Personal Offensive Text', 'Geographical Offensive Text', 'Religious Offensive text', 'Crime Offensive Text', 'Entertainment, Sports, Meme Tiktok, and others'. By combining two large datasets for this research and employing Bengali BERT, the best feasible outcome has been achieved. This paper indicates the complete results of the combined two different datasets and classified into nine segments, while the proposed Bengali BERT models achieved the highest accuracy of 0.706 and a weighted f1 score of 0.705 in the identification and classification tasks.
Mayeesha Humaira, Shimul Paul, Md Abidur Rahman Khan Jim, Amit Saha Ami, and Faisal Muhammad Shah, "A hybridized deep learning method for bengali image captioning." International Journal of Advanced Computer Science and Applications, volume 12, pages 698–707.The Science and Information Organization, 2021, doi: 10.14569/IJACSA.2021.0120287.
Faisal Muhammad Shah, Mayeesha Humaira, Md Abidur Rahman Khan Jim, Amit Saha Ami, and Shimul Paul , "Bornon: Bengali Image Captioning with Transformer-based Deep learning approach." SN Computer Science Journal, volume 3, Article number: 90, Springer, 2022, doi: https://doi.org/10.1007/s42979-021-00975-0.
Faisal Muhammad Shah, Sajib Kumar Saha Joy, Farzad Ahmed, Tonmoy Hossain, Mayeesha Humaira, Amit Saha Ami, Shimul Paul, and Md Abidur Rahman Khan Jim, Sifat Ahmed, "A Comprehensive Survey of COVID-19 Detection Using Medical Images." SN Computer Science Journal, volume 2, number 6, pages 1--22, Springer, 2021, doi: https://doi.org/10.1007/s42979-021-00823-1.
Amit Saha Ami, Mayeesha Humaira, Md Abidur Rahman Khan Jim, Shimul Paul, and Faisal Muhammad Shah, "Bengali image captioning with visual attention." In 2020 23rd International Conference on Computer and Information Technology (ICCIT), pages 1–5, 2020, doi: 10.1109/ICCIT51783.2020.9392709.
Showni Rudra Titli, Shimul Paul "Automated Bengali abusive text classification: Using deep learning techniques" presented at International Conference on Advances in Electronics, Communication, Computing and Intelligent Information Systems (ICAECIS-2023)